Everything you need to know about Splitting NCCL Communicators
MPI allows to create a new communicator by splitting an existing one into a sub-communicator, which can make our program dynamically select a subset of computing nodes to involve in the collective communication operations, such as all-reduce and all-gather operations. NCCL also has a similar feature, but it is not well-documented yet.
TL;DR
Since NCCL relies on MPI to run on multiple nodes, the following example code is based on MPI Programming Model. Assume there are 4 CUDA GPUs and 4 corresponding MPI ranks. This code performs all-reduce operation within the first two and the last two ranks simultaneously.
1 |
|
This code can be compiled and run on my machine with these commands,
1 | nvcc -ccbin mpic++ test.cu -o test -L/usr/local/cuda/lib -lnccl |
Note: Using
nvccto compile MPI code is not a common practice. It is recommended to compile it withmpic++from a CUDA-Aware MPI variant.
The output of this program should be,
1 | [rank0] result: 1 # 0 + 1 = 1 |
The key is ncclCommInitRank. Suppose only a subset of ranks initializes the communicator with the same unique ID belonging to one of them. In that case, this communicator will ignore other ranks that are not in this subset.
Usage of ncclCommInitRank
Official API explanation:
Creates a new communicator (multi thread/process version). rank must be between
0andnranks-1and unique within a communicator clique. Each rank is associated to a CUDA device, which has to be set before callingncclCommInitRank.ncclCommInitRankimplicitly synchronizes with other ranks, so it must be called by different threads/processes or usencclGroupStart/ncclGroupEnd.
In addition to the official instructions, we should also know,
- Each unique ID should only be used once.
ncclGetUniqueIdcan be invoked multiple times, and it will return a different unique ID each time. Meanwhile, the unique ID generated before is still working.- It is safe to communicate within disjoint subsets of nodes simultaneously.
- Using NCCL to perform inter-GPU communication concurrently with CUDA-aware MPI may create deadlocks.
Performance
Moreover, I also evaluate the influence on performance bring by sub-grouping.
The testbed is,
- AWS
g4dn.metalinstance with 8x NVIDIA Tesla T4 GPUs. - Shipped with AWS Deep Learning AMI
- OS: Ubuntu 18.04 (Kernel Version: Linux 5.4)
- CUDA Toolkit: 11.0 (Driver Version: 450.119.03 )
First of all, I would like to emphasize the GPU topology of this bare-metal machine.
Note: We should extract the topology information from physical machines instead of virtual machines since the hypervisor may fuzz the result due to security reasons.
1 | # nvidia-smi topo -m |
It looks like a balanced tree topology. We could expect two neighbor GPUs will have higher communication efficiency.
1 | UPI |
The result below is measured on the root rank, and each experiment is repeated 5 times. Meanwhile, the environment CUDA_VISIBLE_DEVICES was set to reorder GPUs binded to MPI ranks. CPU binding remains unset.
And the meaning of the notations on communicators is,
0/1: Only one communicator performing all-reduce on physical GPU 0/1.0/1 + 2/3: Two communicators are working at the same time, and each of them perform all-reduce on two GPUs independently.0-7: Equivalent to0/1/2/.../6/7.
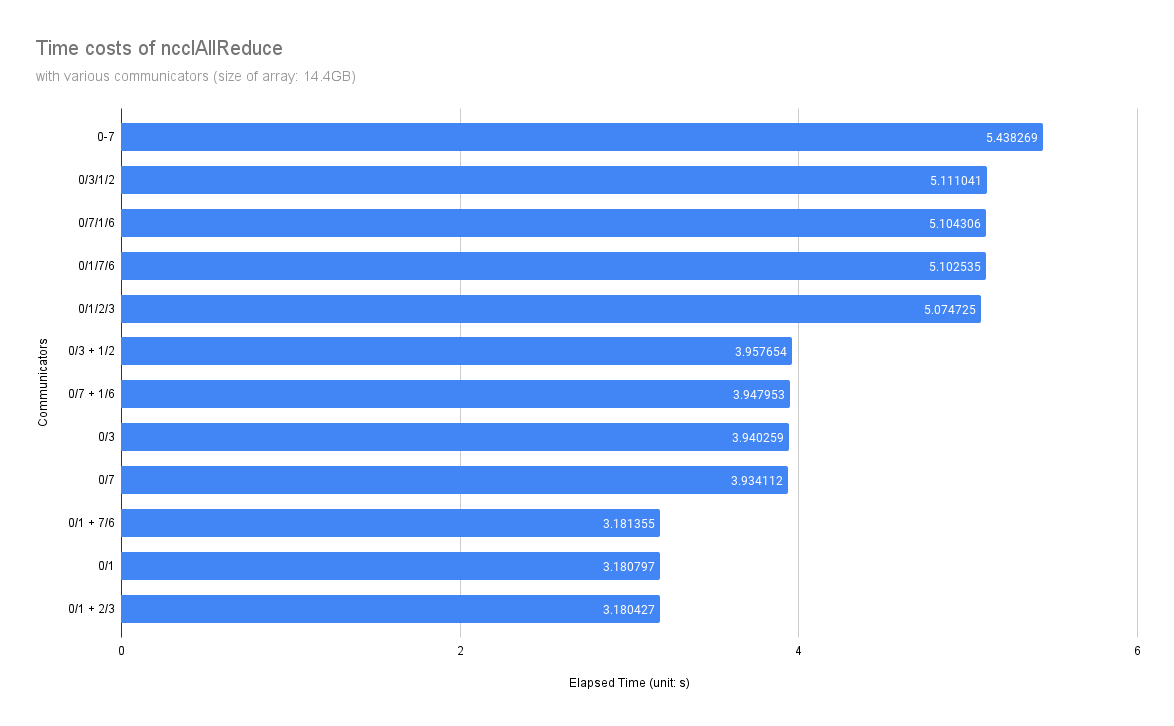
From the result above, we can conclude that,
- GPUs are working at PCIe Gen3 x8 mode as the PCIe Switch splits one PCIe x16 slot into two x8 slots.
- Double checked by
nvidia-smi --query-gpu=pcie.link.gen.current --format=csvandsudo lspci -vvv
- Double checked by
- The GPU Topology will significantly affect the performance of all-reduce.
- The topology that NVIDIA DGX adopt should obviously accelerate collective communication operations.
- The interference between two concurrent communicators is not quite noticeable.
- UPI bus is not a bottleneck when two PCIe Gen3 x16 devices (PCIe Switches) transmit a large data chunk over UPI bus.