Design of TensorFlow XLA Sharding System
Recently, a SOTA sharding approach, GSPMD/GShard, was proposed and it provides an intuitive interface to partition a large array on arbitrary dimensions, while utilizing sharding propagation algorithms to automatically infer the partitioning strategy for tensors without user-specified sharding specifications. This document introduces the design and the implementation of XLA Sharding System.
HloSharding Object
First of all, we need a way to represent sharding specifications using programming language. XLA designed an object to do such a thing, and this object contains numerous variables and a set of supporting functions to configure itself. Some attributes of HloSharding are listed below.
1 | // File: tensorflow/compiler/xla/service/hlo_sharding.h |
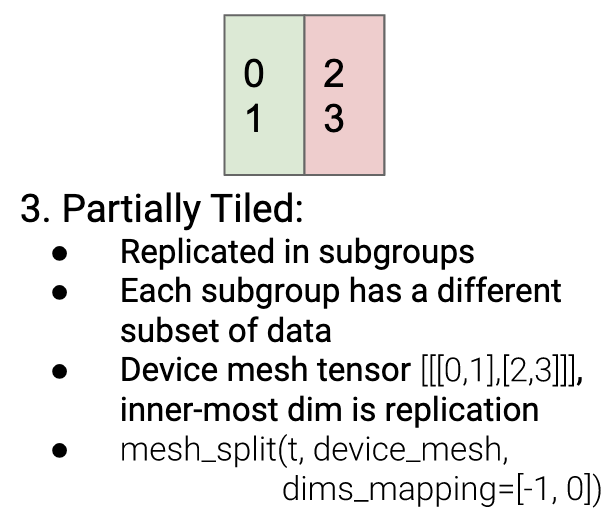
Array<int64> tile_assignment_ here is multi-dimensional with arbitrary shape. {devices=[2,1,2]2,3,5,7} means the shape of tile_assignment_ is [2,1,2], while the values are {2,3,5,7}.
std::vector<HloSharding> tuple_elements_ probably was designed to specify the sharding specifications of outputs.
I am not aware of what the roles of maximal_, tuple_elements_ are. Is there any body know that?
Note that each single object could be shared by multiple instructions. By doing this, the cost of creating and maintaining several instances with the exact same contents could be eliminated.
Extended HLO IR Attribute
The original implementation of XLA added the attribute std::shared_ptr<const HloSharding> sharding_ to the class xla::HloInstruction, which is declared in tensorflow/compiler/xla/service/hlo_instruction.h. A common usage of this HLO Instruction Attribute is to declare sharded tensors. Here is a sample HLO IR code with sharding attributes. Note that the Propagation Algorithm may fill in this attribute for those instructions without it.
1 | primitive_computation_add.6 { |
Note: this HLO IR code is compiled from this JAX Frontend code
1 |
|
This example illustrates a lambda function takes a replicated tensor as the input, and splits this tensor by invoking custom-call, then performs the calculation.
SPMD Partitioner
You might notice that in the previous example, the instructions invoking operators (e.g. reduce.10) don’t contain sharding attributes. That leads to a critical question, how a regular operator reacts to sharded tensors. The solution of XLA is introducing SPMD Partitioner, which is mainly responsible for converting a full-sized operator into a partition-sized operator by adding necessary collective communication primitives to lower-layer IR code, and the partitioner also converts the inputs of operators from global tensor symbols with sharding to local tensor symbols without sharding specifications.
We could find some clues in tensorflow/compiler/xla/service/spmd/spmd_partitioner_test.cc.
1 | TEST_F(SpmdPartitioningTest, DotPartialContracting2) { |
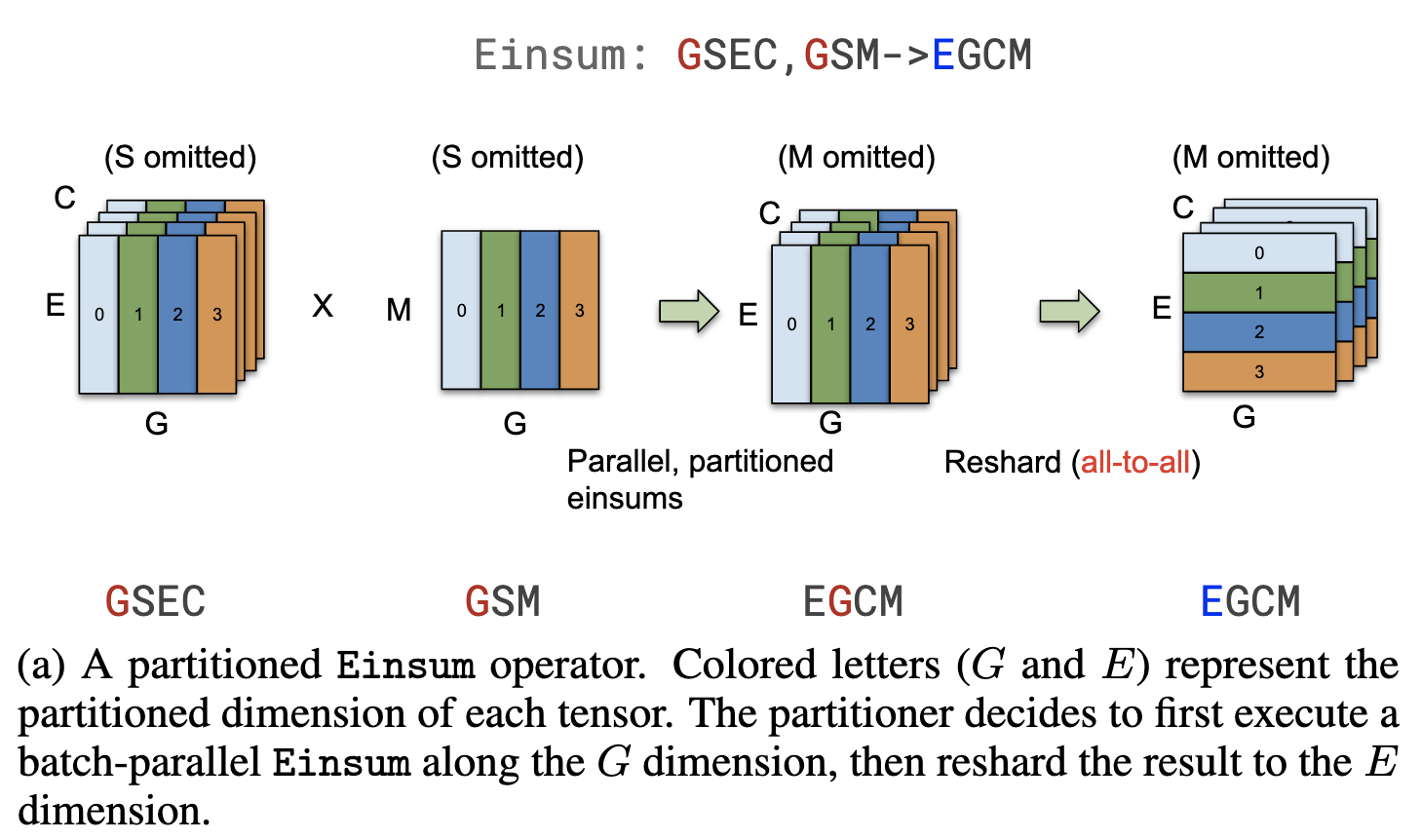
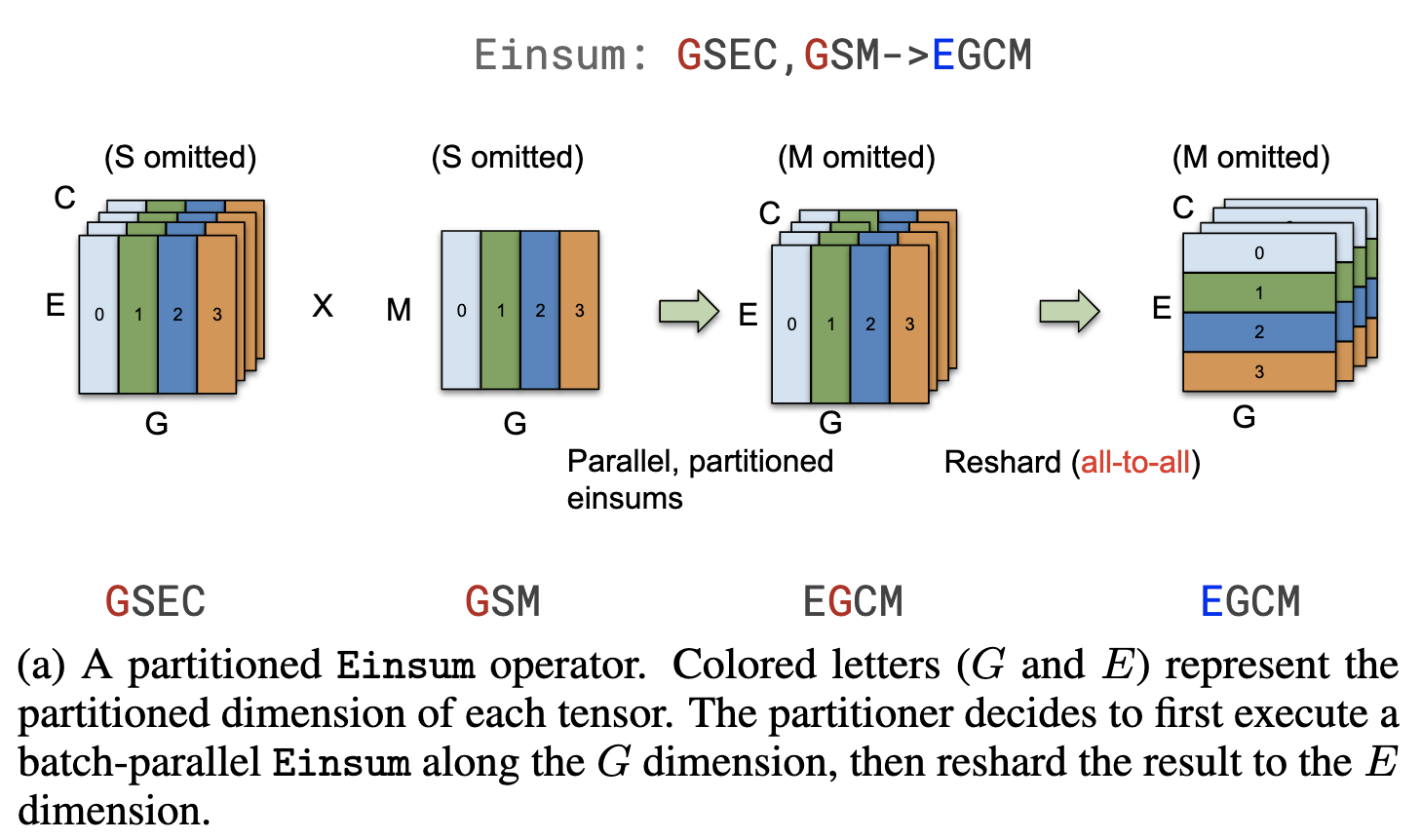
Two inputs, lhs and rhs, are tensors partitioned in the way that the figure describes. Thus, after partitioning the computation, the lhs is unwarpped, and its shape changed from f32[24, 100] to f32[24,50]. And at the end of file, AllReduce was added to collect the partial results.
Sharding Propagation Algorithm
The system should be able to figure out an optimal sharding specifications for the remaining tensors without user’s annotations. An ideal partitioning plan can reduce the communication amount, reduce memory footprint, and improve the performance.
Some unit tests written in tensorflow/compiler/xla/service/sharding_propagation_test.cc are intuitive examples.
1 | TEST_P(ParameterizedMetadataTest, BroadcastForwardPass) { |
It clearly shows that the system inferred the sharding specification of broadcast is {devices=[1,2,2,1]0,1,2,3}according to its input with the attribute {devices=[1,2,2]0,1,2,3}. Note that this test is called BroadcastForwardPass, there also exists a test named BroadcastBackwardPass, which is to say the propagation should be on both directions.
Reference
GShard: https://arxiv.org/abs/2006.16668
GSPMD: https://arxiv.org/abs/2105.04663
Julia DistributedArrays.jl: https://juliaparallel.github.io/DistributedArrays.jl/latest/index.html